


Future-proofing architecture for pivots and AI
The pace of change in software development continues to accelerate. Teams are adapting not only to new tools, but also to rising expectations for flexibility, maintainability, and speed – especially as AI-assisted development becomes more common.
In my own work, this shift has changed how I design systems and structure code. The focus is no longer just on delivering features, but on building systems that can evolve without creating ongoing friction.
After nearly two decades of building software and coaching teams, I’ve adopted a set of architectural practices that reshaped how I approach development. These practices emerged gradually, driven by recurring challenges like merge conflicts, brittle abstractions, bloated services, and frontends that were more complex than necessary. What follows is an overview of the approaches I use today to build systems that remain flexible as requirements change.
Organizing code by use case with vertical slices
Many applications organize code by technical role. Controllers live in one area, models in another, and services in their own layer. While this structure is familiar, it often spreads a single feature across multiple parts of the codebase, making it harder to understand and modify over time.
Vertical slice architecture takes a different approach by organizing code around use cases instead of technical types. Each slice contains everything needed to support a specific capability, such as creating a referral or updating a record.
When an issue arises, there is no need to trace logic across multiple layers. The relevant code is already grouped together. This structure also helps prevent scope creep. When slices stay small and focused, it becomes more difficult to introduce unrelated behavior into existing code. As a result, teams can work more independently, and changes are easier to review and understand in context.
Defining slices through event modeling
A common challenge with vertical slices is determining where one slice ends and another begins. Event modeling provides a practical way to define those boundaries.
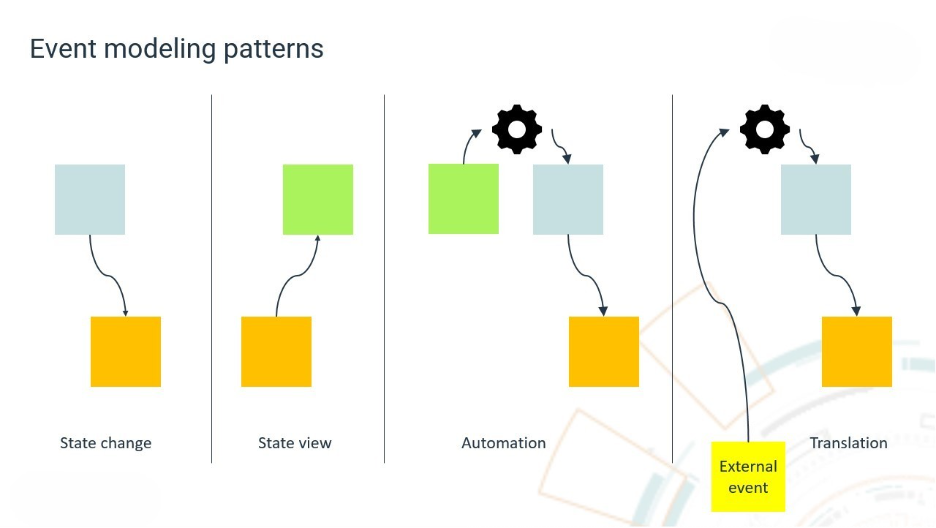
Event modeling maps how data flows through a system from input to storage to output. It uses a small set of core concepts: commands represent an intention to change the system, events represent what has already occurred, and views represent how data is read or displayed.
By connecting these elements, teams gain a clearer understanding of how data moves and evolves. These diagrams go beyond documentation. They create shared understanding across both technical and non-technical stakeholders and make boundaries easier to identify. Each state change and output naturally points to a focused unit of responsibility.
Preserving history with event sourcing
Event sourcing changes how systems store data. Instead of saving only the current state, the system records each meaningful change as a sequence of events. This approach preserves context that is often lost in traditional models.
The benefits are practical and immediate. Teams can analyze historical behavior without redesigning schemas. System state can be reconstructed at any point in time, which improves debugging and investigation. In practice, this makes it easier to rebuild projections, resolve issues, and introduce new reporting without relying on incomplete data.
Event sourcing also works well with read-optimized views. By separating how data is written from how it is queried, systems can remain both flexible and performant.
Simplifying the frontend with Datastar
On the frontend, I’ve shifted away from complex single-page applications in favor of a simpler approach using Datastar.
Datastar enables reactive, push-based interfaces built on server-rendered HTML with minimal JavaScript. Updates are delivered as fragments, and the library applies them directly in the browser.
This approach prioritizes web-native technologies. HTML provides structure, web components encapsulate behavior, and CSS handles transitions. The result is a responsive user experience without the overhead of large frameworks or complex build pipelines.
A practical path forward
Taken together, these practices support a different approach to system design. Rather than trying to predict future requirements, the focus is on building systems that can adapt as those requirements evolve.
They also align well with AI-assisted development, where smaller, well-defined contexts make it easier to generate, test, and refine code. For teams preparing for future pivots, the goal is not certainty—it is adaptability.
Key takeaways
The good news is that these ideas can be adopted incrementally. Teams can apply them to a single feature and expand from there.
- Use event modeling as a shared design tool. Map commands, events, and views early to align teams before assumptions are built into code.
- Organize code using vertical slices. Grouping by use case reduces coupling and supports parallel development.
- Treat data as a long-term asset. Event sourcing preserves history and supports evolving reporting and analysis needs.
- Simplify the frontend where possible. Server-driven updates and web-native tools can deliver responsive experiences without heavy frameworks.
